Prompt Eval Framework
Data-Driven Prompt Optimization
A testing framework for prompt iteration. Six prompt versions, three copywriting frameworks, LLM-as-judge scoring, and statistical analysis. 95% platform compliance.
Overview
A rigorous system for generating compliant Meta ads. YAML messaging frameworks, batch generation across prompt versions, LLM-as-judge scoring, and Streamlit validation with stakeholders.
Challenge
Prompt engineering is usually vibes-based. Change a word, eyeball the output, repeat. I wanted data: batch testing, statistical significance, systematic iteration toward measurable goals.
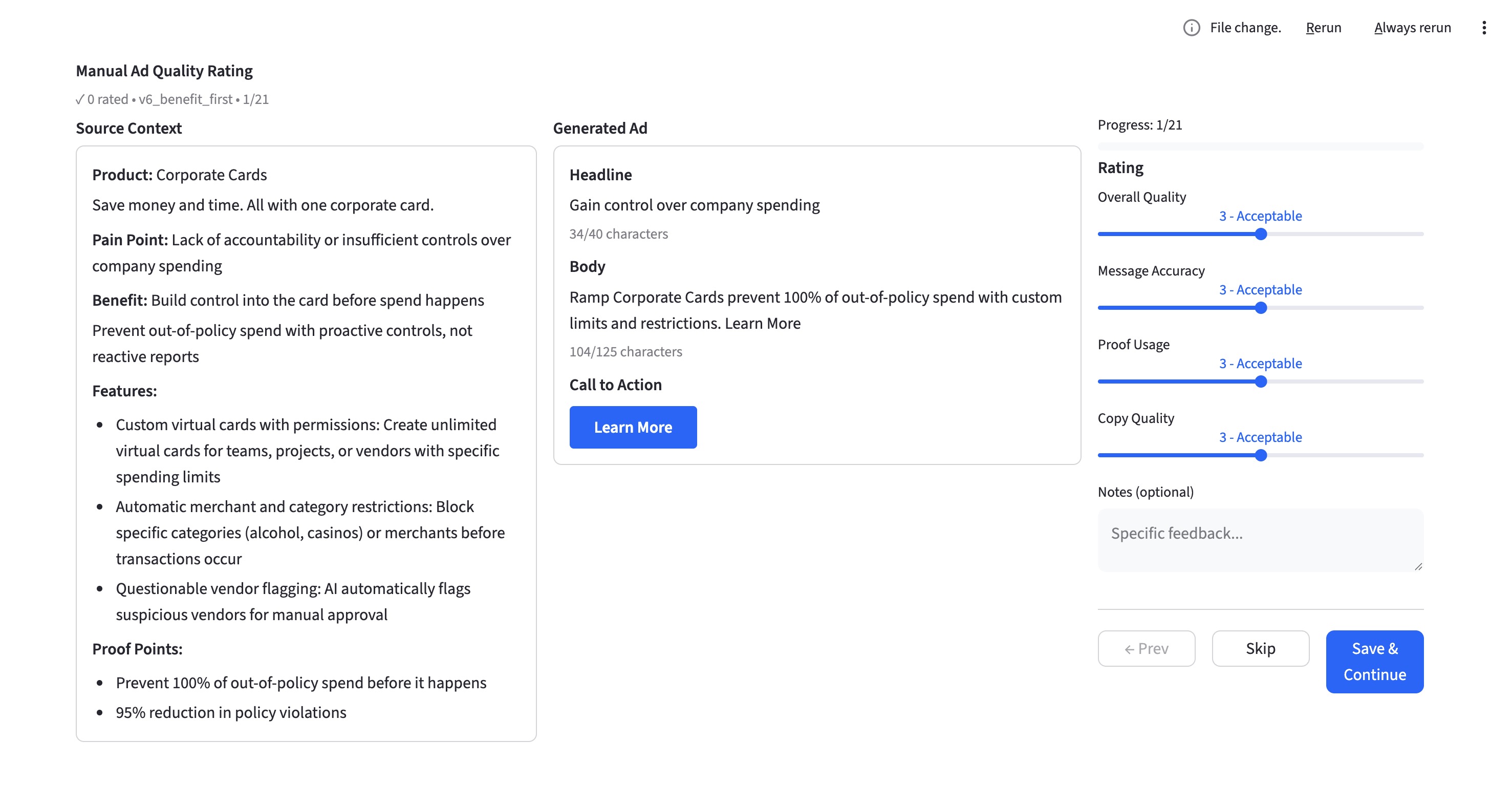
Approach
Created YAML messaging frameworks as single source of truth: pain points, benefits, features, proof points. Every ad traces to strategy.
Built batch generation across 6 prompt versions and 3 copywriting frameworks. 21 test cases produced 100+ ads per iteration.
Implemented two-layer evaluation: deterministic checks (character limits, CTA) plus LLM-as-judge scoring (relevance, brand alignment, persuasion).
Added Streamlit validation for stakeholder ratings. Side-by-side with messaging context, manual scores calibrate the LLM judge.
Outcome
95.2% platform compliance (up from 84.8%). Identified systematic failures: "Get started for free" CTA pushed ads over limit. No statistical difference between frameworks (p=0.96). Discovered 95% ceiling requiring few-shot learning.